Контент (англ. content — содержимое) - информация, а именно, текст, изображения, видео, файлы, которые расположены на сайте.Он должен быть:
- Дающим наиболее полный и понятный ответ, решающим проблему человека: будь то поднять настроение, покончить со сложной дилеммой или приобрести качественный товар.
- Вызывающим доверие.
- Релевантным, то есть соответствующим запросу пользователя поисковой системе.
- Необходимой длины.
- Актуальным.
- Без использования скрытых фрагментов, таких как:
- текст одного цвета с фоном,
- текст скрыт изображением, располагаясь позади него,
- размер шрифта равен значению 0.
- Структурированным и разнообразно оформленным, а именно легко наглядно воспринимаемым:
- главные мысли выделены цветом или жирностью, чтобы пользователь сфокусировал на них внимание. Не забывайте, что веб-страницы не читаются, а мельком просматриваются.
- через теги заголовков h1...h3 реализована структура статьи,
- предложения объединены в абзацы, между которыми присутствует пустая строка,
- использованы списки, цитаты, таблицы,
- применены картинки, инфогра́фика, видеоролики, аудиозаписи. Изображения играют большую роль. Так, один читатель данного блога попросил перевести символы на скриншоте, на котором был изображён редактор Blogger.
- Уникальным и оригинальным (нельзя, чтобы он был восстановленным с умерших сайтов или взятый с ресурсов под фильтрами). Поисковики за этим пристально следят, крайне нежелательно относятся к дубликатам и применяют санкции за использование схожих материалов. Представьте ситуацию: вы задаёте запрос и видите в результатах выдачи один и тот же ответ. Изучение же нескольких по разному раскрывших тему источников позволит сформировать более точное и широкое понимание вопроса. Проверить неповторимость текста возможно вставив в форму поиска его фрагмент в кавычках (посмотрите пример).
Дублирование контента можно наблюдать не только при размещении данных на разных сайтах, но и при повторении информации на двух и более URL-адресов одного веб-проекта. Вот эксперимент на devvver.ru о негативе внутренних дубликатов и как этим могут воспользоваться конкуренты.
Рассмотрим какие инструменты у нас есть в борьбе с этим недугом.
Ссылки на страницу
Единственный стопроцентный способ не дать проиндексироваться странице - не размещать на неё ссылки, пусть даже текстовые и не добавлять её в аддурилки Яндекса, Google и т.п.
Файл robots.txt
Текстовый файл robots.txt (например, для моего блога) прекрасный инструмент для управления индексацией. Справка Yandex, Google. Но если Гугл найдёт ссылку на закрытый в robots.txt URL, то он добавит его в выдачу.

Из-за этого здесь нужно вписывать только те веб-документы, до которых нельзя добраться иным путём, например, фид сайта. И, конечно, sitemap для более качественной и быстрой индексации востребованных страниц.
HTTP заголовок
URL не будет проиндексирован, если код статуса HTTP показывает 404 или 301. А для Google, ещё и когда присутствует строка
X-Robots-Tag: noindex
Мета-теги robots
Это главный инструмент, потому что работает он и для Яндекса и для Гугла одинаково. На странице, доступ к содержимому которой должен быть запрещён, указывается:
<meta name="robots" content="noindex"/>
Атрибут rel="canonical"
Обязательный атрибут rel="canonical" подсказывает предпочитаемый из нескольких web-документов с очень похожим содержанием, например, http://shpargalkablog.ru/2010/07/kontent.html и http://shpargalkablog.ru/2010/07/kontent.html?showComment. Второй поисковая система проигнорирует, поскольку подчинится строке:
<link href='http://shpargalkablog.ru/2010/07/kontent.html' rel='canonical'/>
Для изображений сайта rel="canonical" можно указать в файле .htaccess.
Яндекс.Вебмастер
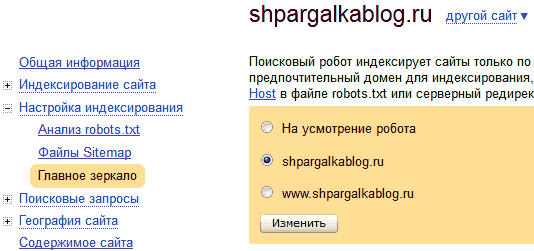
В Яндекс.Вебмастере-"Настройки индексирования"-"Главное зеркало" необходимо указать основной домен, а именно с www или без него.
Инструменты для вебмастеров Google
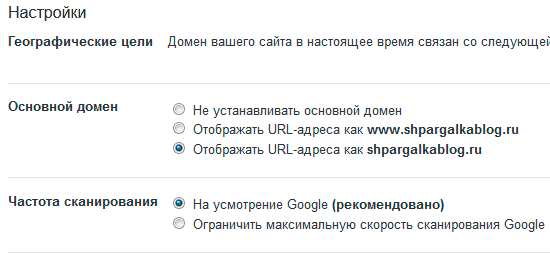
Такую же процедуру необходимо сделать в Инструментах для вебмастеров Гугла-"Конфигурация"-"Настройки".
В "Конфигурация"-"Параметры URL" можно заблокировать индексацию страниц, которые содержат в своём URL-адресе определённые фрагменты, например, "default". Эта функция разработана в основном для интернет-магазинов, где навигация реализуется с помощью URL, и где один продукт относится к двум или трём категориям. (подробнее).

media="print"
Не нужно создавать отдельную версию для печати ![]() . Стили можно скорректировать с помощью media="print".
. Стили можно скорректировать с помощью media="print".
Удаление дубликатов, находящихся в индексе по ошибке
Несмотря на предпринятые меры, поисковые роботы могут проиндексировать нежелательную страницу. Задав запрос
site:shpargalkablog.ruпросмотрите всю выдачу, особенно с опущенными результатами в Гугле. В идеале этой надписи не должно быть:

Опущенные результаты надо убирать вручную. Для Yandex воспользуемся формой удаления страницы, а для Google нужно зайти в "Инструменты для веб-мастеров"-"Оптимизация"-"Удалить URL-адреса"-"Создать новый запрос на удаление".